Gartner verwacht sterke kostendaling voor AI-interferentie
De kosten voor het uitvoeren van inferentie op grote taalmodelen (LLM’s) met één biljoen parameters zijn tegen 2030 met meer dan 90% lager gedaald ten opzichte van 2025, verwacht marktonderzoeker Gartner. Deze daling wordt mogelijk gemaakt door verbeteringen in halfgeleiders en infrastructuur, innovaties in modelontwerp, efficiënter gebruik van chips, gespecialiseerde hardware voor inferentie en het gebruik van edge-devices voor specifieke toepassingen.

AI-tokens zijn de eenheden van data die generatieve AI-modellen verwerken. Zij worden in de analyse van Gartner gedefinieerd als 3,5 byte aan data, wat overeenkomt met ongeveer vier tekens. Volgens Gartner komen de lagere kosten voort uit een combinatie van efficiëntere halfgeleiders en infrastructuur, innovaties in modelontwerp, hogere chipbenutting, toename van gespecialiseerde hardware voor inferentie en het gebruik van edge-devices voor specifieke gebruiksscenario’s. Will Sommer, senior directeur analist bij Gartner, licht toe: “Deze kostenverbeteringen zullen worden aangedreven door een combinatie van efficiëntieverbeteringen in halfgeleiders en infrastructuur, innovaties in modelontwerp, hogere chipbenutting, meer gebruik van gespecialiseerde hardware voor inferentie en de toepassing van edge-devices voor specifieke gebruiksscenario’s.”
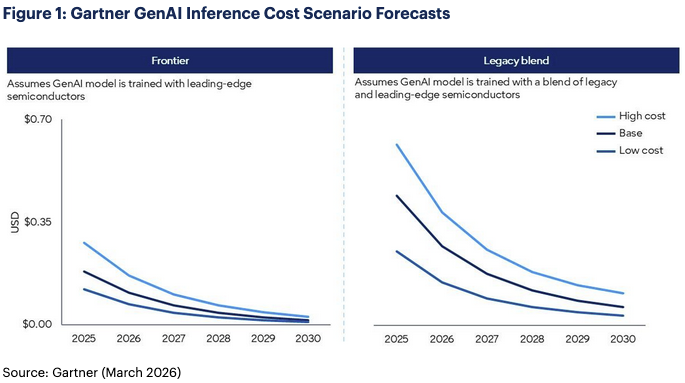
Gartner verwacht dat LLM’s in 2030 tot honderd keer kostenefficiënter zijn dan de eerste modellen van vergelijkbare omvang die in 2022 werden ontwikkeld. De voorspelde resultaten zijn gebaseerd op twee scenario’s voor halfgeleiders: frontier-scenario’s waarbij modelverwerking is gebaseerd op de nieuwste chips, en legacy blend-scenario’s waarbij een mix van beschikbare halfgeleiders wordt gebruikt. De kosten in de blend-scenario’s liggen aanzienlijk hoger dan in de frontier-scenario’s, vanwege de lagere rekenkracht.
Leidt niet tot democratisering van geavanceerde AI
Hoewel de kosten per token voor AI-providers naar verwachting dalen, voorspelt Gartner dat deze besparingen niet volledig worden doorgegeven aan zakelijke klanten. Bovendien gaan geavanceerde AI-toepassingen aanzienlijk meer tokens vereisen dan huidige mainstreamtoepassingen. AI-agents hebben bijvoorbeeld vijf tot dertig keer meer tokens per taak nodig dan een standaard AI-chatbot en kunnen veel meer taken uitvoeren dan een mens met behulp van AI.
Sommer waarschuwt: “Chief product officers mogen de daling van de kosten voor standaardtokens niet verwarren met de democratisering van geavanceerd redeneren. Terwijl gestandaardiseerde intelligentie richting bijna-nulkosten gaat, blijven de rekenkracht en systemen die nodig zijn voor geavanceerd redeneren schaars. CPO’s die architectonische inefficiënties vandaag maskeren met goedkope tokens, zullen morgen moeite hebben om AI-agents op te schalen.”
Workloads verdelen over diverse modellen
Volgens Gartner wordt waarde vooral gegenereerd door platforms die workloads kunnen coördineren over een divers portfolio van modellen. Routinetaken met een hoge frequentie moeten worden toegewezen aan efficiëntere, kleine en domeinspecifieke taalmodelen, die beter presteren dan generieke oplossingen tegen een fractie van de kosten wanneer ze zijn afgestemd op gespecialiseerde workflows. Dure inferentie met geavanceerde modellen moet strikt worden beperkt en uitsluitend worden ingezet voor hoogwaardige, complexe redeneertaken.



Meer over Gartner



Over Wouter Hoeffnagel
